Spindl - 如何真正做到鏈上歸因 Onchain Attribution
原文連結: https://blog.spindl.xyz/p/how-to-really-do-onchain-attribution

如何真正進行鏈上歸因
「因少了一枚釘子,丟了一隻鞋;因少了一隻鞋,丟了一匹馬;因少了一匹馬,敗了一場戰;因敗了一場戰,丟了一個王國;所有這些都是因為少了一枚馬蹄鐵釘。」 - 詹姆斯·鮑德溫,《馬蹄鐵釘》(1912)
什麼是歸因?
歸因是尋找導致世界上某個特定事件發生的因果「原因」的問題。就商業邏輯而言,目標是在競爭激烈的注意力市場中選出贏家,這也是市場商業模式的主要輸入。簡而言之,誰因為帶來了這個使用者(及其相關收入)而獲得報酬,他們獲得多少報酬?這是任何行銷系統的核心問題;也是最難回答的問題。
截至撰寫本文時,Spindl 剛測量到 10 億個事件(鏈上和鏈下都有),每天的增長速度約為 200 萬到 500 萬個事件(註1)。我們最大、運行時間最長的「使用者」(關於這一點的更多資訊將在我們下週的「身份」文章中說明)是 DEX 聚合器 Hashflow,它不知何故在 595 個活躍日內產生了 105,954 個事件(註2)。Vertex,一個永續合約 DEX,單獨就產生了超過 1 億個追蹤事件(!) 。為什麼我們要費心追蹤所有這些上游事件?僅僅查看使用者從哪裡點擊就夠了嗎?不,遠遠不夠。
與傳統分析平台中通過 URL 參數進行的會話追蹤不同 - 這通常與真正的歸因混淆,但在實際應用中卻大相逕庭 - 行銷歸因是黏性的。如果使用者是由上游應用程式或發布者啟用的,則無論他們多少次(或從哪裡)回到廣告服務,該使用者都將保持歸屬於該來源。
在 Web2 中,接觸點和轉換數據是眾所周知的:使用者通常會訪問網站/行動應用程式(觸發經過良好測量的事件,例如點擊或應用程式安裝),然後進行購買。有整個市值數十億美元的公司 - AppsFlyer、Branch、Facebook 和 Google 的歸因系統 - 唯一的目標就是吸收大量的事件數據並在數據洪流上運行歸因邏輯。「最後觸及」或「瀏覽次數」等相互競爭的方法決定了誰在歸因對抗中勝出(以及誰失敗),廣告玩家所做的許多事情都是為了利用歸因方法來達到自己的目的。
在 Web3 中,我們看到基於區塊鏈的開放性出現了各種有趣的新模式:
- 轉換事件通常根本不會發生在網站或手機應用程式上。例如,在 DEX 上買賣 NFT 或購買代幣通常都是公司的轉換目標,即使這些操作並非發生在應用程式控制的體驗上。甚至可能不是人類在執行這些操作。沒有鏈上測量,您將錯過大部分動作。
- Web3 具有新的使用者獲取活動形式,例如任務(使用者因試用協議而獲得報酬)和 NFT 空投(使用者獲得直接發送到其錢包地址的免費資產或代幣)。這些是新穎的機制,使用標準 Web2 廣告技術將完全被忽略或歸因錯誤。
- Web3 事件可用於驅動 Web2 事件。例如,我們看到許多遊戲使用代幣空投或獎勵來鼓勵手機應用程式安裝:鏈上操作是驅動下游事件(鏈下或鏈上)的上游操作。
- dApp 可以使用其他 dApp 作為其應用程式的獲取渠道。例如,我們看到許多「爭奪」活動,其中 dApp 將向在競爭平台上活躍的使用者提供回扣。區塊鏈的公開交易記錄使各種目標定位和激勵措施成為可能,而這些措施在 Web2 中大多是不可能的。
- 每個人同時都是廣告主與發布者,既是某人的下游,也是某人的上游。舉個具體的例子來說,Safe (Spindl 的客戶) 使用我們來衡量他們的上游渠道,同時也與另一位 Spindl 客戶 Morpho 進行聯合行銷活動,而雙方都想了解自己的上游與下游狀況。此外,還有 Morpho 的資金池運營者(例如 Gauntlet)也在運行自己的行銷漏斗,這些漏斗會經過 Morpho 以及其他渠道。在 Web2 中,行銷漏斗是單向的,而在 Web3 則是一組相互嵌套的層級結構(註3),這既增加了測量的難度,也在某些方面讓測量變得更容易。我們目前還沒遇到行銷漏斗形成循環的情況,但這遲早會發生。
鏈上歸因如何實作
歸因(Attribution) 是將使用者的旅程提煉為一組加權的使用者接觸點,這些接觸點導致了「轉換」(Conversion)。拋開宗教意味不談,這其實只是行銷人員花錢促成的某個最終事件。接觸點(Touchpoint) 可以是任何事件——例如:從 Twitter 造訪你的網站、你向某個錢包發送的 NFT 空投、或是完成某個鏈上任務——這些都可能導致轉換。需要注意的是,這些事件並不互斥:它們既可能影響使用者如何達成轉換,也可能本身就是一個創造收益的事件。此外,傳統的「行銷漏斗」在 Web3 中往往會以奇特的方式呈現遞迴。
讓我們看看以下典型使用者旅程的例子。我們的目標是確定左邊哪個事件導致了最右邊的轉換事件。
藍色方塊是接觸點,綠色方塊是轉換事件。
關於歸因需要理解的關鍵點是,雖然時間向前發展,但歸因向後運行:轉換事件會觸發對已查看事件的反向邏輯。
這是一個基本的觀察,但值得說明:當用戶看到廣告展示、點擊連結或開始瀏覽您的應用程式時,並不會知道是否會進行轉換所能做的只是向前記錄事件,然後一旦發生轉換事件,就使用連接相關事件的 web2/web3 身份圖譜(註4) 拼湊出一個可能的用戶渠道。
向後回溯的第一步是 「生命證明」(Proof of Life):這名轉換的使用者是本來就活躍的使用者,還是新使用者,或者是可能被重新喚回的使用者?
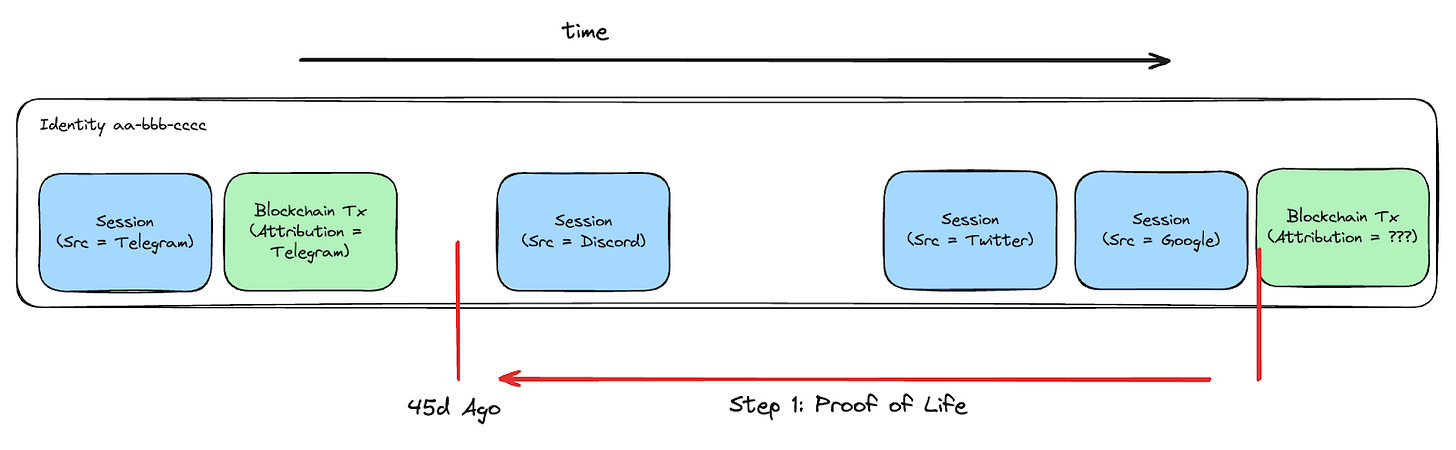
DApp 可以設定自己的 「流失窗口」(Churn Window),即用戶需要在多少天內執行過有意義的活動,才能被視為活躍用戶。一旦用戶被標記為「活躍」,他們就會固定歸因於某個行銷渠道。只有當他們流失時,才有資格被(重新)歸因到其他來源。
在這個案例中,該用戶在過去 45 天內 沒有進行任何有意義的活動,因此被視為流失。而他們的接觸點(僅僅是從 Discord、Twitter 和 Google 點擊進來)並不足以被視為「生命證明」(Proof of Life),也就是說,這些事件不足以讓協議認定該用戶仍然活躍。
接下來,我們會檢查 「回溯窗口」(Lookback Window),看看該用戶最近是否有任何活動可能觸發了他們的復活(Resurrection)。
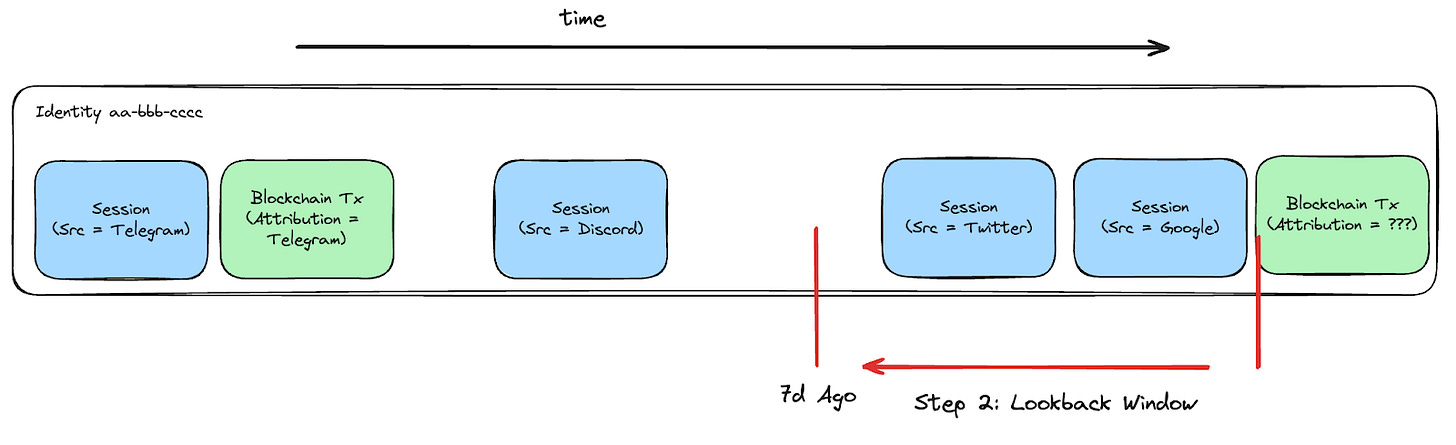
回溯窗口(Lookback Window)會檢索該時間範圍內的所有接觸點,並選擇一個「贏家」。在 Web3 領域,大多數 DApp 預設採用「首次接觸」(First Touch) 模型;我們也支援 「最後接觸」(Last Touch)。這種選擇幾乎像是一種民間傳說式的決定 - 它確實會影響結果,但方式既非線性,也難以預測。
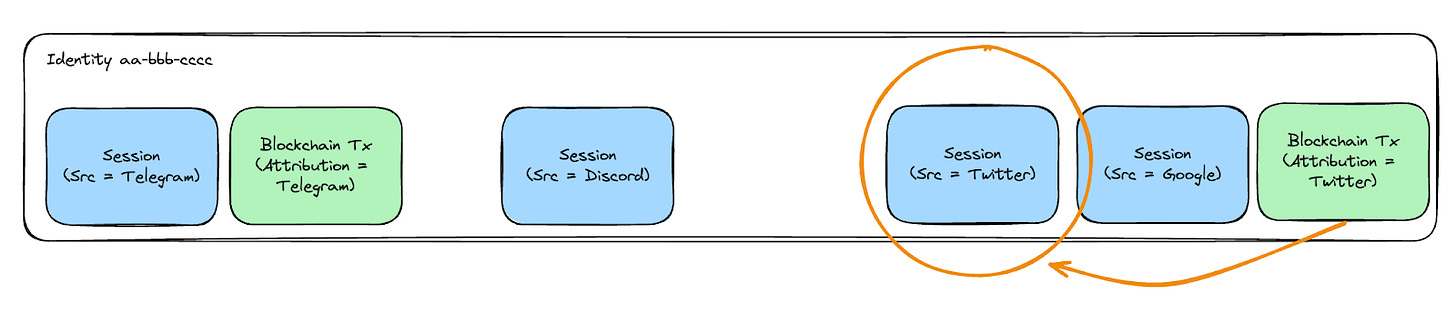
在本例中,「首次觸及」選擇 Twitter 作為區塊鏈交易歸因信用的贏家。
建立歸因
在 Spindl,我們針對歸因(Attribution)的運行方式進行了多次迭代,以應對規模增長、配置需求以及新方法論的挑戰。
最初,我們採用了 「無狀態」(Stateless)模型,這種方式是按需查詢轉換用戶的旅程。在每天處理數萬筆轉換事件的規模下,這種方法相對便宜且高效,讓我們能夠計算歸因、回填數據,並且幾乎能夠即時測試不同的模型。
-- 45 Day Proof of Life
SELECT attribution_channel FROM events WHERE identity = ? AND is_conversion = true AND time > NOW() - INTERVAL 45 DAYS ORDER BY DESC;
-- First Touch Lookback
SELECT session_channel FROM events WHERE identity = ? AND is_touchpoint = true AND time > NOW() - INTERVAL 7 DAYS ORDER BY ASC;
以下是一組簡化的查詢範例,用於定義 「首次接觸」(First-Touch)的無狀態(Stateless) 歸因模型。當一個事件發生時,系統會執行以下步驟:
- 身份識別(Identity) - 根據事件的屬性確定其對應的使用者身份。
- 第一個查詢(First Query) - 如果該使用者已經存在,並且仍處於 流失窗口(Churn Window) 內,則沿用他們先前事件的歸因渠道。
- 第二個查詢(Second Query) - 在歸因/回溯窗口(Attribution/Lookback Window)內檢索相關的接觸點,以確定最終的歸因渠道。
這整個過程是準即時執行的,與新的轉換事件同步運行,不需要中間緩存或預先分類。透過單線程處理所有歸因計算,結果是完全確定性的,易於除錯且可以回放。換句話說,你可以隨時回放事件,找出導致最終歸因結果的「關鍵事件(smoking gun)」。
在最初 30 天的歸因運行後,將事件關聯起來的身份圖譜(Identity Graph)(註5)通常會變得更加穩定,因為我們對現有使用者的識別變得更加清晰。隨著越來越多的客戶達到這個階段,並且客戶的事件量激增(包括鏈上與鏈下),我們轉向了一種更 有狀態(stateful) 的方法。
可以將有狀態歸因理解為:我們透過存儲所有與使用者相關的事件摘要,並維護一系列快速查詢表,來保持一個即時更新的使用者視圖。
在下面的範例中,可以看到新進事件如何更新 「上次見到時間(Last Seen)」以及「流失窗口(Churn Window)」,以對應到該使用者的狀態變化。
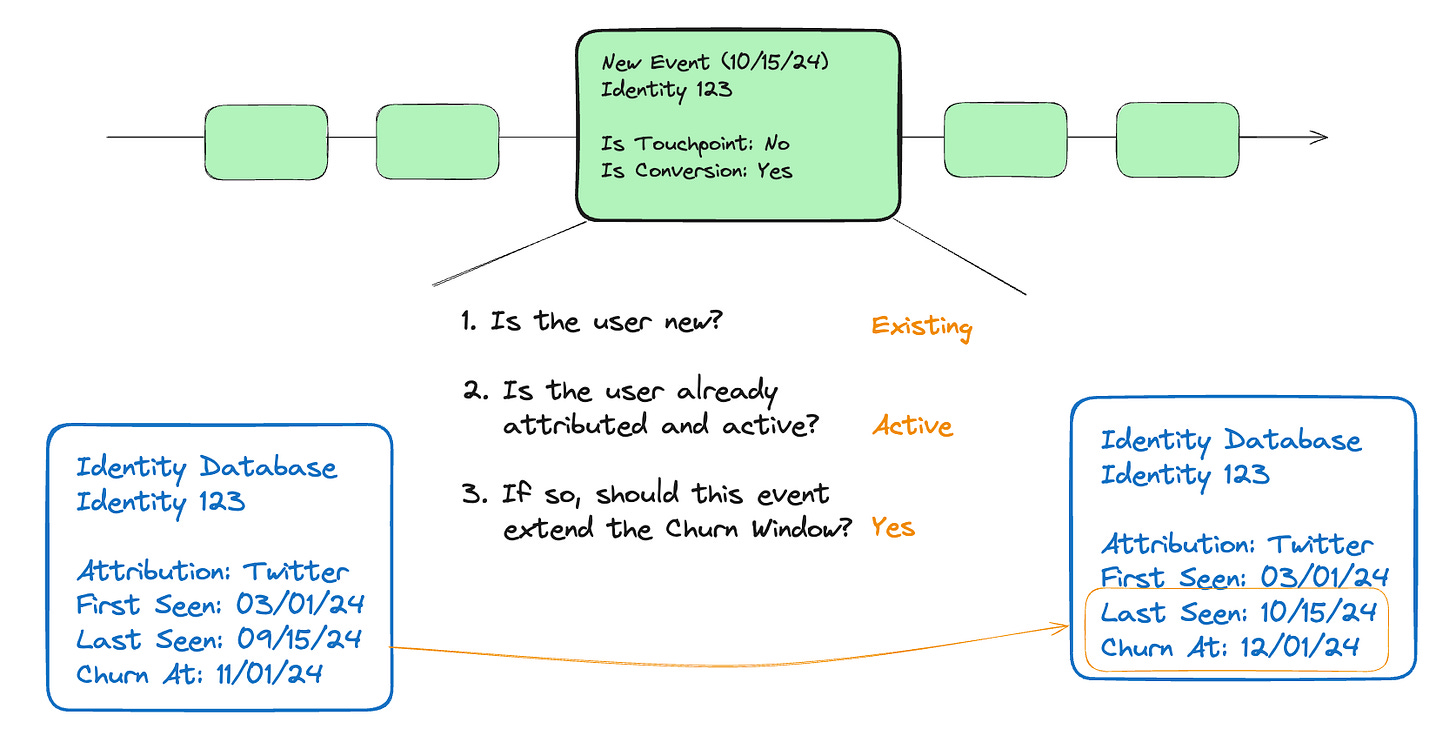
透過以使用者為中心來拆解事件歷史,我們能夠實現並行化處理,因為每個使用者的歸因計算都可以獨立運行。當然,將使用者的完整事件歷史鍵入一個不斷變化且不斷增長的身份圖譜(Identity Graph)顯然不是一種高效的存儲方式,並且可能會變得非常昂貴,因此我們需要在如何存儲數據方面採取更巧妙的方法。
目前,我們的歸因方法運行在一種混合式工作流程中,其中我們以有狀態(Stateful)的方式存儲與每個使用者相關的重要接觸點,例如最新的「生命證明」(Proof of Life,POL)事件以及在特定時間窗口內有效的可歸因事件(Attributable Events)。由於我們的數據管道是以批次處理運行的,我們使用無狀態(Stateless)查詢來整理批次內的數據,並在必要時智能地結合存儲狀態與即時查詢。隨著身份的合併或演變,有狀態存儲會更新,以反映最新的使用者互動,類似於快取的運作方式。
在實踐中,我們的數據處理管道已經演進為當前的解決方案,以應對 Web3 中一些有趣的挑戰:
- 數據及時性(Data Timeliness) - 歸因對數據及時性有一定的嚴格保證,因為順序和時間戳都很重要。除非所有之前的「生命證明」和接觸點都已經被採納,否則我們無法對轉換事件進行歸因。這使得串流解決方案特別容易出錯,並且需要對數據可用性進行嚴格的保證和運行時檢查。
- 延遲數據(Late Arriving Data) - 同時,延遲數據是常態。跨區塊鏈的數據提供商具有不同的 SLA 和延遲,許多第三方數據提供商沒有實時報告功能。雖然我們盡最大努力確保數據以嚴格的時間順序輸入,但我們有多種流程可以處理延遲到達的接觸點數據。正如所述,由於我們無法編輯我們已經支付的任何操作,這是一個需要許多護欄的微妙過程。
- 熱點(Hotspots) - 身份(即我們認為來自同一使用者的相關事件的捆綁)具有更大的差異,我們可以訪問區塊鏈上更多歷史數據。進行數千次交易的 MEV 機器人的「生命證明」數據的處理成本比在新的錢包上進行第一次交易的使用者高出指數倍。
- 合併(Merges) - 由於 Web3 中的身份極具動態 - 鏈上錢包身份相對穩定,而鏈下行為則極為不穩定 - 身份(和歸因)的合併需要在數據建模方面採取創新解決方案,以確保穩定性和準確性。
當我們創立 Spindl 時,我們的目標不僅僅是將 Web2 廣告技術機械地複製到鏈上,而是構建 Web3 中本質上不可能實現的新功能。例如,行銷人的終極目標 - 「多點觸及」(Multi-Touch)歸因模型,可以正確地對使用者發現產品的多種方式進行計算和獎勵,這在鏈上廣告中是完全可行的。一對多支付機制已經具備,而區塊鏈的公開透明數據使得任何人都可以驗證你的高級分數歸因模型是否合理。加密市場正在加速發展廣告技術,從低效的空投(Airdrops)和同樣低效的 CPM 廣告,快速進化到純效能導向的去中心化歸因,在短短幾年內跳躍了 Web2 廣告技術 20 多年的發展。真正的鏈上廣告時代,終於來了。
註
- 所有客戶中歸因最大的渠道(按順序):
- Linktree (!)
- Layer3
- Collab.land(Discord 頻道,Spindl 網絡的一部分)
- YouTube
- 加密貨幣的「使用者」通常很明顯是機器人,但只要它們能夠產生真實的鏈上交易,似乎沒有人在意(更不用說我們即將進入的 AI 代理時代了)。正如我們的一位客戶在會議上聽我們擔憂地解釋為何測量到的轉換事件比頁面瀏覽次數還多(顯然這些不是人類)時所說的:「機器人也是人啊。」更準確地說,是會花錢的機器人。
- 某些事件甚至可以是自我歸因的,使用一種相對簡單的「隨便觸及」(Whatever Touch)歸因方式,僅僅是將 URL 參數寫入鏈上(例如 Gains Network 會在其應用網站上提供一個可選的「推薦碼」欄位)。這基本上是大多數「鏈上歸因」系統的默認方法,但一旦進行多渠道策略,這種方法的缺點就會很快顯現。例如,當一個聚合器(Aggregator)覆蓋掉原本由 KOL 引薦的推薦標籤時,KOL 便無法持續獲得推薦佣金。
- 這個「身份」圖譜(Identity Graph)本質上是將鏈下的接觸點(例如瀏覽器和移動設備)與錢包進行關聯,並長期維持這種多對多的關聯關係。在 Web2 中,跨標識符的全域身份(Global Identity)一直是一個重大問題,而在 Web3 也將同樣重要,特別是當像 Privy 和 Dynamic 這類錢包基礎設施為每個應用生成一個獨立錢包時。
- 在我們下一篇 Spindl Engineering 系列文章中,我們將探討歸因背後的無名英雄 - 身份(Identity)。我們將回答這樣的問題:如何確定來自四個不同應用的使用者會話和兩筆鏈上交易,實際上都來自同一個真實的用戶?