Succinct - 可證明的軟體時代
原文連結: https://writings.succinct.xyz/provable

新興科技在普及過程中,往往遵循著一條顯著一致的道路。首先,該技術處於胚胎階段,具有特定應用性。可用於一些特定任務,但還不足以成為任何人都可以在其上開發的通用架構。出於尋找一套標準的動機,這些標準能為開發人員提供一個可靠構建的框架,工程師和研究人員之間爆發了一系列高風險的意識形態之爭。這些爭論導致了標準化以及技術擴展的可能性。應用程式開發和基礎設施建設加劇,導致廣泛使用。從早期網際網路以來,我們已經看到這種趨勢在許多時代體現出來,從 TCP/IP 到人工智慧等各種技術都是如此。
我們現在正步入網際網路的新時代:可證明的軟體時代。 由於過去十年零知識 (ZK) 密碼學的進步,現在可以通過通用零知識虛擬機 (zkVMs) 驗證可以寫成程式的任意陳述的執行。可證明的軟體為區塊鏈和更通用的計算開啟了一類新的應用程式:透過可驗證的程式碼,我們可以實現對任何計算任務的無信任委託。這對我們如何構建去中心化協議、處理使用者身份和驗證以及設計業務邏輯具有深遠的影響。
回顧科技史,讓我們深入了解可證明的軟體在廣泛整合到世界中的發展軌跡。ZK 最初是高度特定應用的;早期的程式需要編碼成電路,這些電路只能用於單個應用程式。如今,隨著 SP1 等 zkVMs 的出現,我們比以往任何時候都更有信心,可證明的軟體已經找到了其通用解決方案。今年,我們發布了簡潔網路 (Succinct Network) 計畫,該計畫與 SP1 共同設計,為 ZK 證明提供了一個基礎設施和財務激勵層。我們相信 SP1 和簡潔網路的結合是可證明的軟體的正確通用擴展解決方案。
在這篇文章中,我們闡述了我們的核心論點:從特定應用系統到通用標準的轉變,在以往每個軟體時代都催化了基礎設施建設,在可證明的軟體時代也將如此。從早期網際網路和 AI 中特定應用程式到通用框架的轉變示例 (圖 1) 中,我們看到了軟體的統一歷史。這段歷史為我們提供了可證明的軟體未來如何發展的經驗教訓。
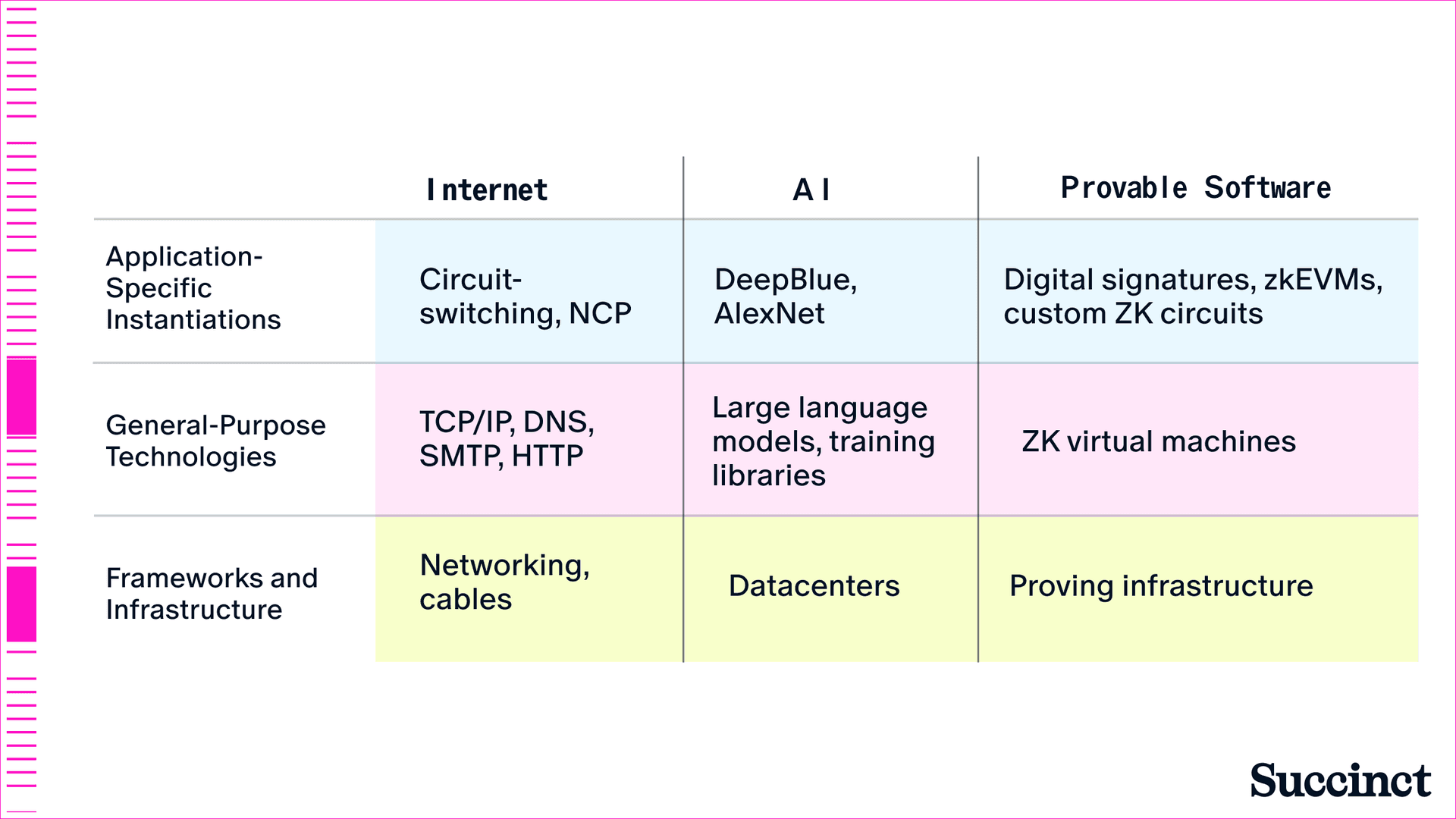
圖 1:軟體從特定應用程式到通用的轉變比較。
特定應用軟體
在本節中,我們將介紹早期網際網路、人工智慧和加密技術的特定應用版本。
早期的網際網路:應用程式專用的封包路由
在大衛·克拉克 (David D. Clark) 的著作《設計網際網路》(Designing an Internet) 中,他概述了編碼網際網路數據包路由層的標準:TCP/IP,這是一種協議,它告訴電腦網路如何將資訊轉換為數據包,然後通過網路傳輸。從家用路由器到企業級節點,所有一切都是基於 TCP/IP 執行的,因此網際網路上的應用程式可以處理各種各樣的數據,從文字、圖像到影片、遊戲。克拉克認為,這些標準的簡單性對於實現這種廣泛的創新至關重要。在 TCP/IP 之前,各種競爭標準造成了混亂和難以控制的開發人員碎片化。換句話說,如果沒有簡單的通用協議來確保數據包的可靠傳輸,我們今天在網際網路上享用的通用應用程式將不可能實現。
儘管 TCP/IP 是一個簡單的協議,但我們不應將其視為全球網際網路普及的「勝利」解決方案。從 20 世紀 60 年代到 90 年代,存在著各種競爭標準,所有這些標準都受到不同的研究計劃和市場力量的推動。「電路交換」例如,被認為是數據包交換的早期競爭對手,並提出了使用電話線路網路容量來傳輸數據的想法。這種方法從根本上來說是特定應用程式的,因此從未流行起來,因為您必須為個別應用程式分配特定的容量。
即使早期的數據包交換也是特定應用程式的。在 20 世紀 60 年代後期,美國國防部使用稱為 NCP (網路控制協議) 的數據包交換協議開發了 ARPAnet。與 TCP/IP 相比,NCP 有著嚴重的局限性。首先,NCP 無法自動繞過失敗的網路鏈路,這在連接的節點數量較少的情況下是可以接受的,但在擴展時顯然會面臨挑戰。
也許最大的限制是 NCP 的「軟體」層與其託管的應用程式之間的緊密耦合。雖然 ARPAnet 支援早期網際網路應用程式(如電子郵件),但它與 NCP 協議緊密耦合。使用者將呼叫「SNDMSG」來發送電子郵件,並呼叫「READMAIL」來閱讀電子郵件——並且系統要求兩位使用者同時在線。電子郵件基本上是「內建協議」的。
簡而言之,網際網路最早的嘗試是特定應用程式的:NCP 協議的開發目的是連接 ARPAnet 上的節點,並且在網路之上構建的應用程式都硬編碼到 NCP 協議本身中。需要進一步的研究 - 以及來自其他框架的競爭 - 才能出現 TCP/IP 標準。
特定應用之人工智能
自艾倫·圖靈 (Alan Turing) 以來,對機器學習通用框架的追求一直是電腦科學領域的北極星。在他 1950 年的論文《計算機與智慧》(Computing Machinery and Intelligence) 中,圖靈闡述了智慧型電腦的目標,該電腦可以像兒童一樣通過「經驗」學習,而不是通過明確的程式設計。但 AI 模型訓練系統的早期實現是特定應用程式的,專為語音識別、西洋棋和圖像識別等功能設計——這反映了當時的計算和演算法限制。
蠻力訓練和明確程式設計是機器學習中早期的主導模型。例如,深藍 (Deep Blue) 在 1997 年成功擊敗加里·卡斯帕羅夫 (Garry Kasparov) 下西洋棋之前,經歷了近十年的開發。IBM 在 1986 年和 1987 年開發的西洋棋引擎的第一個版本,其動力來自於如何實現更好的計算閘利用率和並行搜尋的研究,這兩個功能是提高預測位置數量,從而提高西洋棋引擎效能的關鍵。到研究人員在 1997 年發布深藍時,他們已經實現了更為複雜的架構:他們的數據集包含超過 70 萬場國際象棋大師賽。雖然該模型架構在擊敗卡斯帕羅夫方面「成功」,但它也代表了當時機器學習的局限性:該模型無法泛化,它只能下西洋棋。
在接下來的十五年中,機器學習的其他突破接踵而至,但所有這些都受到特定應用程式方法的限制。早期在數字識別和語音識別等原始任務上訓練神經網路的方法受到數據集大小以及在訓練和運行模型推理方面的硬體能力的限制。人工智慧經歷了很長一段時間的基準測試增量改進,但沒有真正的突破性進展。
2012 年,AlexNet 的發布被譽為該領域的一項重大突破,該模型從 ImageNet 數據集中訓練圖像分類,其方法包括模型架構(一個具有 6000 萬個參數的多層卷積神經網路,當時規模很大)和在 GPU 上劃分模型訓練的方法。
但與之前的例子一樣,AlexNet 也受到限制——雖然它被認為是模型複雜性方面的一步,但它只能進行圖像識別,並且缺乏執行其架構未指定的任何通用任務的能力。在該領域達到接近「通用智慧」之前,需要進一步的研究。
特定應用之密碼學:從簽章到 SNARK
作為特定應用程式軟體實現早於通用實現的第三個例子,我們來看一下密碼學。第一個主流密碼學協議,數位簽名,是在 20 世紀 70 年代提出的。在他們 1976 年的論文《密碼學的新方向》(New Directions in Cryptography) 中,惠特菲爾德·迪菲 (Whitfield Diffie) 和馬丁·赫爾曼 (Martin Hellman) 提出了一種公開金鑰簽名方案,該方案滿足至今仍是關鍵要求的安全屬性:該系統必須能夠可靠地保證隱私和驗證(代表訊息簽名者),並且在計算上是安全的,因為它無法被尋求偽造簽名的外部人員暴力破解。
1978 年,羅納德·李維斯特 (Ronald Rivest)、阿迪·薩莫爾 (Adi Shamir) 和倫納德·阿德曼 (Leonard Adleman) 提出了 RSA 簽名方案,該方案介紹了公開金鑰加密的高級演算法實現,以及金鑰簽名長度的建議(鑑於當時的計算限制,他們估計他們的演算法將需要大約 38 億年才能破解)。這些系統解決了密碼學中的三個基本問題:金鑰交換、加密和數位簽名。
同樣,重要的是要注意,這些簽名在其實現中是「特定應用程式」的,旨在解決特定的密碼學問題。即使公開金鑰簽名開始整合到網際網路中(首先是早期形式,例如 20 世紀 90 年代的 Netscape 等瀏覽器中 RSA 金鑰交換和驗證的實現,後來在整個網路中以 ECDSA 等簽名方案的形式出現),它們仍然受到限制。隨著網際網路而流行的密碼學簽名方案設計用於一種用例:保護和驗證網路上的數據。
在網際網路歷史上,密碼學一直被視為網路的安全層,而不是本身的一種應用程式。雖然比特幣、以太坊(以及以太坊的擴展解決方案)和其他區塊鏈已經以數位簽名、默克爾承諾和零知識證明(用於離線驗證和隱私)的形式生產化了密碼學,但我們仍然處於可證明的軟體的早期階段——我們相信這是密碼學的通用框架。
零知識證明使密碼學可程式設計,從數位簽名等特定應用程式方法中脫穎而出。但是,即使是零知識證明的早期實現也是特定應用程式的。它們涉及證明以太坊虛擬機的正確執行,或設計僅驗證特定類型應用程式輸出的證明。這些方法是倒退的,導致特定應用程式的實現應該是一種通用技術。
優化的單用途 ZK 電路要求開發團隊在孤島中工作,設計特定於其網路和用例的演算法。這樣,密碼學就讓人想起網際網路的早期時代,當時存在許多無法互操作的競爭協議,或者人工智慧的早期時代,當時研究人員在達到通用深度學習之前追求一次性實現訓練模型。但正如我們已經找到並擴展了這些技術的通用形式一樣,可證明的軟體的通用形式也即將到來。
轉向通用軟體
我們現在講述了使早期技術準備好被廣泛採用的轉折點:尋找通用解決方案。這種解決方案通常作為早期實現的可程式設計、標準化版本出現,並使開發變得更加容易。
早期的網際網路:標準化
在 20 世紀 70 年代,ARPAnet 的研究人員開始探索克服 NCP 強加的互操作性缺乏的方法,並最終找到了構建當今網際網路的 TCP/IP 標準。1983 年,ARPAnet 正式轉向 TCP/IP,1989 年,ARPAnet 正式退役,工作轉向一個稱為 NSFnet 的組織,該組織利用 TCP/IP 的互操作性開始連接研究機構和其他超級電腦中心。
在 20 世紀 80 年代,DNS 在 TCP/IP 之上實現,為使用者提供了一種在網際網路上註冊預定地址的方法。在此之前,網路使用者必須發送郵件給一個人——資訊科學研究所的喬恩·波斯特 (Jon Postel)——才能將他們的姓名映射到域名地址,這種方法當然無法擴展。其他通用應用程式框架也開始出現:1982 年標準化的 SMTP 催生了現代電子郵件,而 1991 年推出的 HTTP 則催生了現代網頁。
只有在 TCP/IP 標準化之後,應用程式層才能真正起飛 (圖 2)。到 20 世紀 90 年代末,數據包可以傳輸的「數據」封裝繼續變得越來越廣泛,從靜態文字和電子郵件到圖像、音訊、語音、影片和遊戲。到 2000 年,線上網站超過 1700 萬個,使用者超過 4.13 億 - 這證明了強大的標準確保應用程式層能夠蓬勃發展。
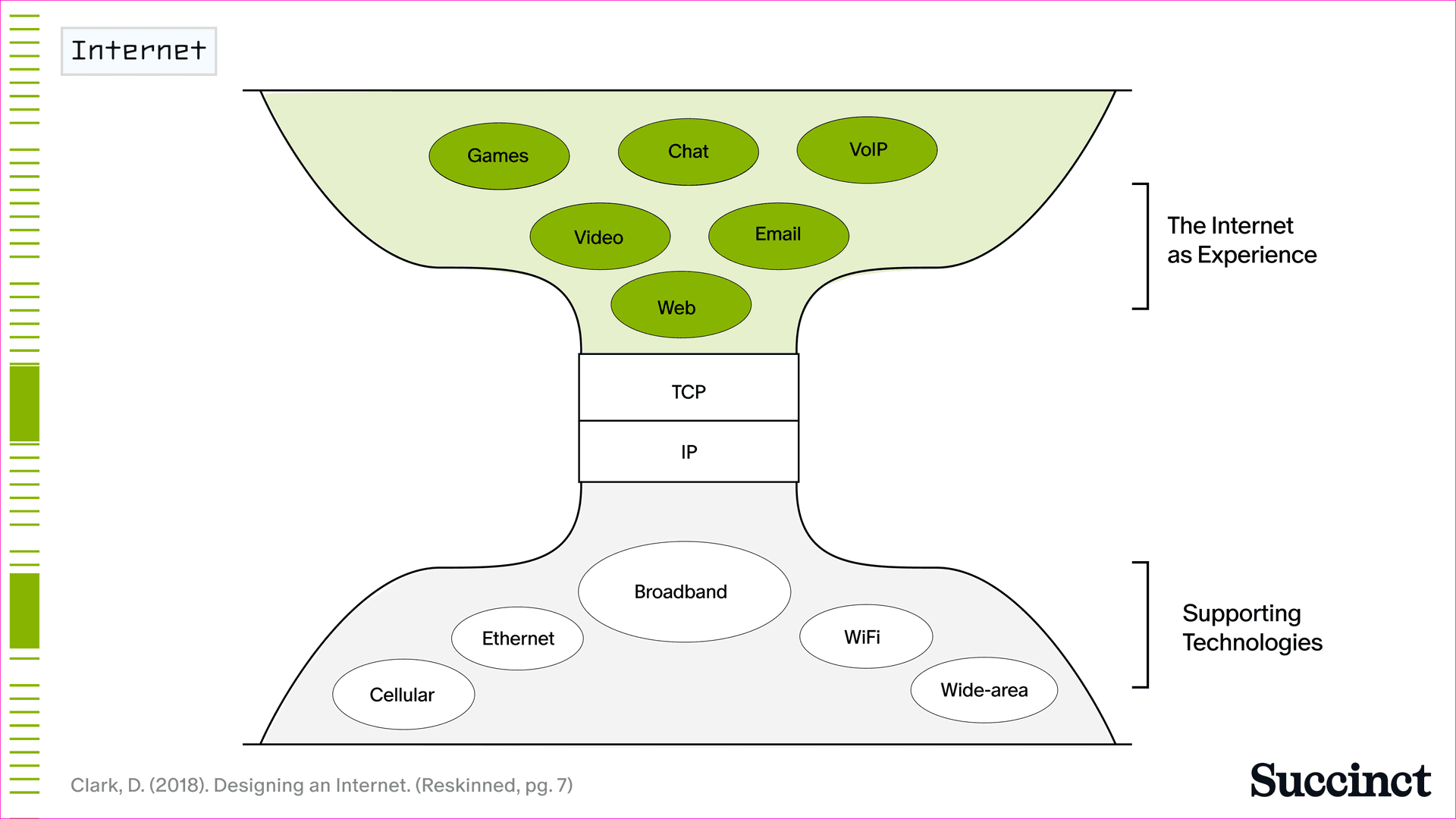
圖 2:網際網路圍繞 TCP/IP 標準化,使應用程式層蓬勃發展。
通用人工智能
在人工智慧採用週期的這個階段,擴展假設已得到很好的理解:當您將高質量且穩健的數據集與改進的模型架構和擴展計算相結合時,深度學習模型會變得更好。但是,為了達到這一點,需要在軟體層進行大量的標準化。
2015 年,深度學習開發達到了一個轉折點,當時 Google 開源了 TensorFlow,它成為最具影響力和廣泛採用的通用神經網路訓練框架之一。TensorFlow 標準化了常用操作的實現:在其發布之前,研究人員必須從頭實現反向傳播、梯度下降和其他基本演算法。Meta 於 2016 年發布的 Pytorch 是另一個開源模型框架,它使通用訓練運動更加主流。PyTorch 引入了可以即時修改的動態計算圖,並允許研究人員簡單地編寫 Python 程式碼。
2017 年,Google 發布了著名的論文《注意力就是你所需要的》(Attention is All You Need),該論文為深度學習引入了一個新的抽象層:變壓器 (transformer)。這項發明導致更有效率的模型訓練和跨 GPU 的過程更容易並行化,並導致了大型語言模型的發展,這是一個簡單地操作文字序列的「通用單元」智慧。2019 年發布的 GPT-2 代表了圍繞語言模型規模和實現的這些學習成果的結晶,並且值得注意的是,它證明了在廣泛數據集上訓練的語言模型可以在沒有明確訓練的情況下執行各種任務。
一旦清楚地認識到,訓練庫和變壓器模型的結合可以導致能夠進行阿蘭·圖靈在 1950 年首次闡述的通用學習的大型語言模型,大量的精力就投入到擴展這種方法中。GPT-2 具有 15 億個參數,與 GPT-3(1750 億個參數)和 GPT-4(估計約為 1.8 萬億個參數)相比微不足道。以前,人們必須訓練單獨的模型來解決特定任務,例如分類或翻譯。有了 GPT-3 和 GPT-4,我們第一次有了通用模型,使在單個架構中編碼大量任務成為可能。
構建通用 AI 模型的抽象層意味著,今天任何人都可以通過利用基於變壓器的 LLM 的 API 來構建 AI 應用程式(更不用說來自 Hugging Face 和 Meta 等團隊的開源 AI 模型的激增)。最重要的是,從生成式 AI 模型到編碼助手,再到整個企業,如今都在構建 (圖 3)。
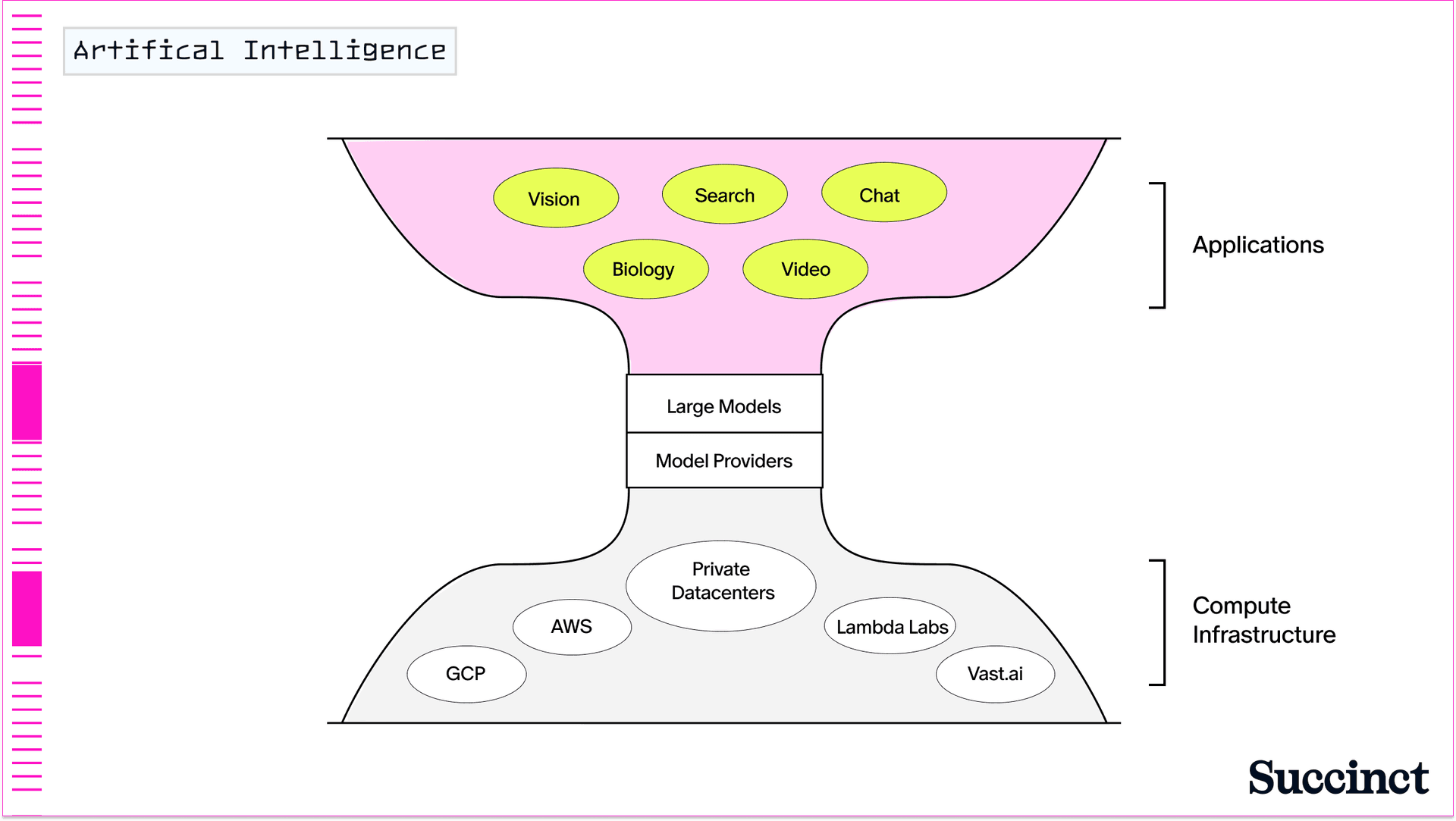
圖 3:通用人工智慧。
通用可證明軟體之路
我們現在已經到了可以生成簡潔證明來證明任何任意計算的程度。今年早些時候,我們宣布了 SP1,這是一個 zkVM,它不僅可以證明 rollup 執行,還可以證明任何應用程式的正確執行,從而為構建 rollup、跨鏈橋、協處理器、隱私解決方案等的團隊縮短了上市時間。就像 TCP/IP 是網際網路的通用形式,模型訓練框架與基於變壓器的架構相結合導致了通用 LLM 一樣,zkVM 是可證明的軟體的通用形式。
SP1 引入了一些新穎的優化功能,使其成為證明軟體的理想選擇。它編譯成 RISC-V,這是一種在計算中流行的開源指令集架構。它附帶通用的密碼學預編譯,從而減少了證明生成所需的 RISC-V 週期計數。也許最重要的是,它允許開發人員使用 Rust 編寫和驗證任何確定性程式,這比 Solidity 等安全性較低且表達能力較弱的語言有了巨大的提升。
在過去幾個月中,我們看到使用 SP1 作為可證明的軟體的通用 zkVM 的團隊數量急速增加。Taiko 使用它來證明主網區塊,而像 Strata 這樣的 rollup 團隊則在其之上構建。Polygon 等網路使用 SP1 作為其互操作性協議 Agglayer 的底層證明系統。Succinct 還實現了一種機制,可以用 SP1 有效性證明替換 OP 堆疊錯誤證明,這將被 Mantle 採用,並且正在與 Celestia 合作為其網路開發類似的證明系統。
隨著我們進入可證明的軟體時代,我們正在目睹標準化和向通用實現的轉變。我們正在從特定應用程式的密碼學協議和零知識證明的實現(例如在單個區塊鏈 rollup 中使用的那些)轉向可以處理任何類型計算的通用證明系統。與此同時,我們將看到圍繞證明系統標準化的基礎設施 (圖 4)。我們將在下節中討論這一點。
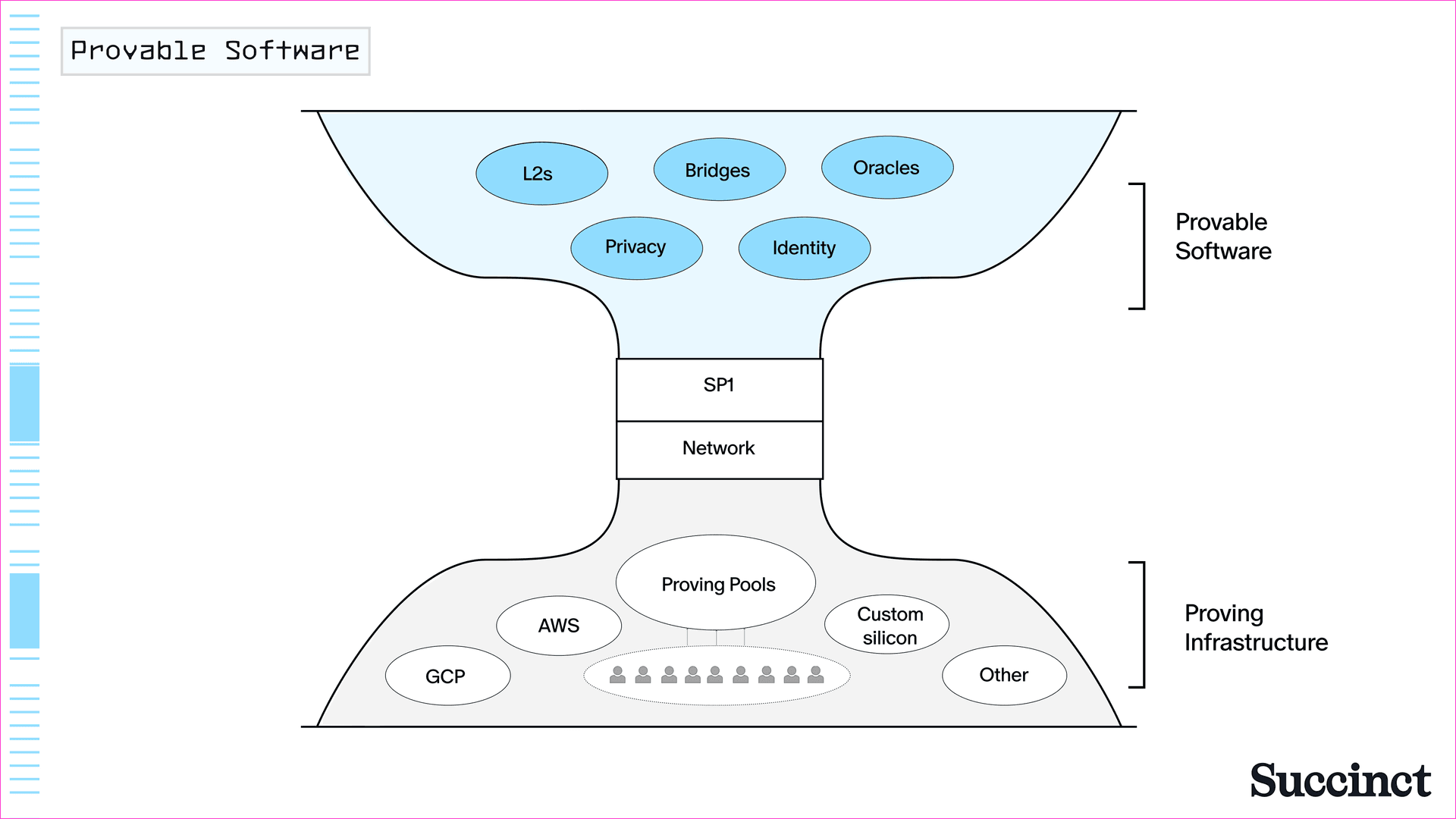
圖 4:像 SP1 這樣的 zkVMs 是可證明的軟體的通用形式,啟用新的應用程式。
基礎建設擴展:擴充軟體
在所有之前的技術中,向通用軟體的轉變之後,都會伴隨著相應的基礎設施建設,使應用程式能夠以可靠、經濟高效的方式接收服務,同時為終端使用者提供軟體。歷史告訴我們,這發生在早期網際網路和人工智慧中。我們相信,隨著可證明的軟體被廣泛採用,這種趨勢將繼續下去。
建立早期網際網路
基礎設施建設歷來都伴隨著參與者之間的激烈競爭。從 1996 年到 2000 年網路泡沫破裂結束,AT&T、Sprint 和已經不存在的 ISP(如 Worldcom、Level 3、Global Crossing)至少投入了 5000 億美元(根據通貨膨脹調整後約為 9340 億美元)來鋪設光纖電纜和建設無線網路。TCP/IP 的成功驗證了電信主管大衛·艾森伯格 (David Isenberg) 所說的「愚蠢網路」哲學 - 保持核心網路簡單,並將智慧推向邊緣。這影響了電信公司如何看待其基礎設施投資,因為它允許他們專注於鋪設大量光纖和部署更簡單的 IP 路由器。這在網路泡沫時期尤其重要,因為部署速度至關重要。
換句話說,需要在軟體層進行標準化才能讓網際網路的通用應用程式層得以普及。在那之後,網路的操作層,以網路建設和可預測的基於訂閱的定價的形式,也變得清晰了。
人工智能基礎建設
AI 模型基礎設施建設的軌跡類似。研究人員找到了可以簡單地連接到更多計算的 AI(LLM)通用架構,這使得擴展大型語言模型變得可預測。
雖然公開沒有提供模型公司在建設方面的支出金額的權威性和審計數字,但可以拼湊出支出大概會是什麼樣子。Chat-GPT 的訓練成本超過 1 億美元。Anthropic 的執行長證實,一個將花費 10 億美元訓練的模型正在研發中。馬克·祖克伯格 (Mark Zuckerberg) 相信 Meta 將需要 10 倍 Llama 3(擁有 4050 億個參數)的計算能力來訓練 Llama 4。自 2024 年初以來,NVIDIA 的數據中心業務(包括其 GPU 的銷售)收入已超過 790 億美元 - 反映了對訓練和推理的巨大需求。
其他用於按需訓練和推理的第三方基礎設施提供商也已出現:Lambda、Coreweave 等公司,更不用說 AWS、GCP 和 Azure 等雲提供商,它們都提供 GPU 租賃服務,其定價模型遵循按需或預留容量模型。隨著測試時間計算(或在查詢模型時使用的額外計算)的興起,我們預計將出現更多基礎設施提供商來滿足需求。
可證明軟體的基礎建設
同樣,zkVM 也需要自己的「擴展假設」來滿足 rollup 團隊和其他應用程式構建者已經表達的需求。當大多數區塊鏈領域的人想到「擴展」時,他們會想到 L1 和 L2 的效能。在 Succinct,我們考慮到擴展方面,指的是提供高效能的 zkVM 加上防審查和防宕機的證明基礎設施。我們最近宣布了 Succinct Network,這是一種去中心化證明的新模型,它利用了過去軟體時代基礎設施建設中的觀察結果。該網路認識到需要一個協調的基礎設施層,讓競爭的證明者能夠滿足證明吞吐量需求,並在通過 SP1 生成證明的同時,提高終端使用者的成本和效能。與其他 zkVMs 相比,SP1 證明的生成成本最多可降低 10 倍,從而使網路上的潛在 GPU 和 CPU(更不用說 FPGA 等其他潛在的硬體實現)獲得更好的規模經濟。
我們預計 ZK 證明基礎設施將遵循與歷史上其他技術類似的軌跡,其中開發出標準化的通用解決方案,然後通過基礎設施進行擴展。但是,證明建設的規模不會像之前的基礎設施時代那樣自上而下。我們預計將看到來自整個生態系統的證明者,從硬體團隊到數據中心運營商,提供最終使終端使用者體驗更有價值的服務,而不是少數幾家 ISP 和電信公司,或者由幾家大型公司運營的分佈式 GPU 數據中心。
可證明軟體的未來
回顧過去的時代,有趣的是,在技術早期階段存在的特定應用程式實現可以通過其通用對應物重新實現。在 ARPAnet 和 NCP 協議時代,早期硬編碼的電子郵件後來變成了 SMTP——許多電子郵件客戶端都可以在其上構建的框架。早期的特定應用程式 AI 模型現在是可以基於更通用的 LLM 構建的應用程式的類型(例如,您可能會看到一個基於 GPT-4 構建的西洋棋機器人)。並且,zkEVM、橋樑、身份驗證等的早期特定應用程式電路現在可以很容易地作為使用 SP1 構建的應用程式來實現。
除了這些歷史上的架構相似性之外,一個更大的重點是明確的:網際網路、人工智慧和可證明的軟體都是具有深遠社會影響的技術。網際網路圍繞能夠支援一系列應用程式和硬體實現的 TCP/IP 標準化。有了網際網路,我們獲得了數據和資訊的即時傳輸。人工智慧圍繞利用人類正在傳輸和收集海量數據這一事實的訓練庫和架構標準化。我們能夠將網路的數據轉化為知識和智慧。
今天,網際網路正在發展,並且有兩種力量在起作用:人工智慧的加速採用和可證明的軟體世界的早期景象。規模經濟優勢使現有企業受益,並導致人工智慧的中心化效應。可證明的軟體使得驗證計算和智慧成為可能,而無需依賴受信任的中介。隨著智慧由於世界各地企業的擴展努力而變得普遍,讓所有軟體都可證明將成為必要。使這個未來成為可能的技術已經出現了。